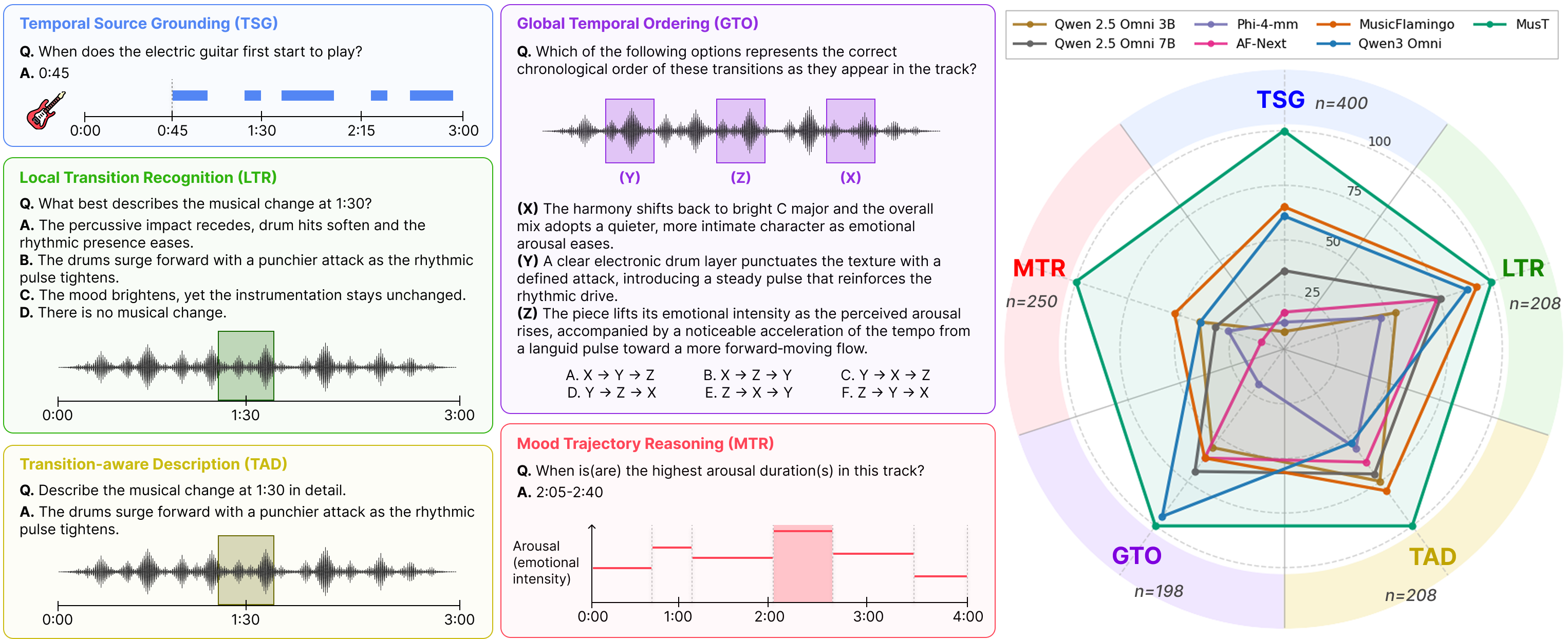
Five Temporally Grounded Music QA Tasks
Interactive Examples
Explore representative examples from MusTBench Each example shows the audio, ground truth, and model predictions together.
Leaderboard
MusT Training Pipeline
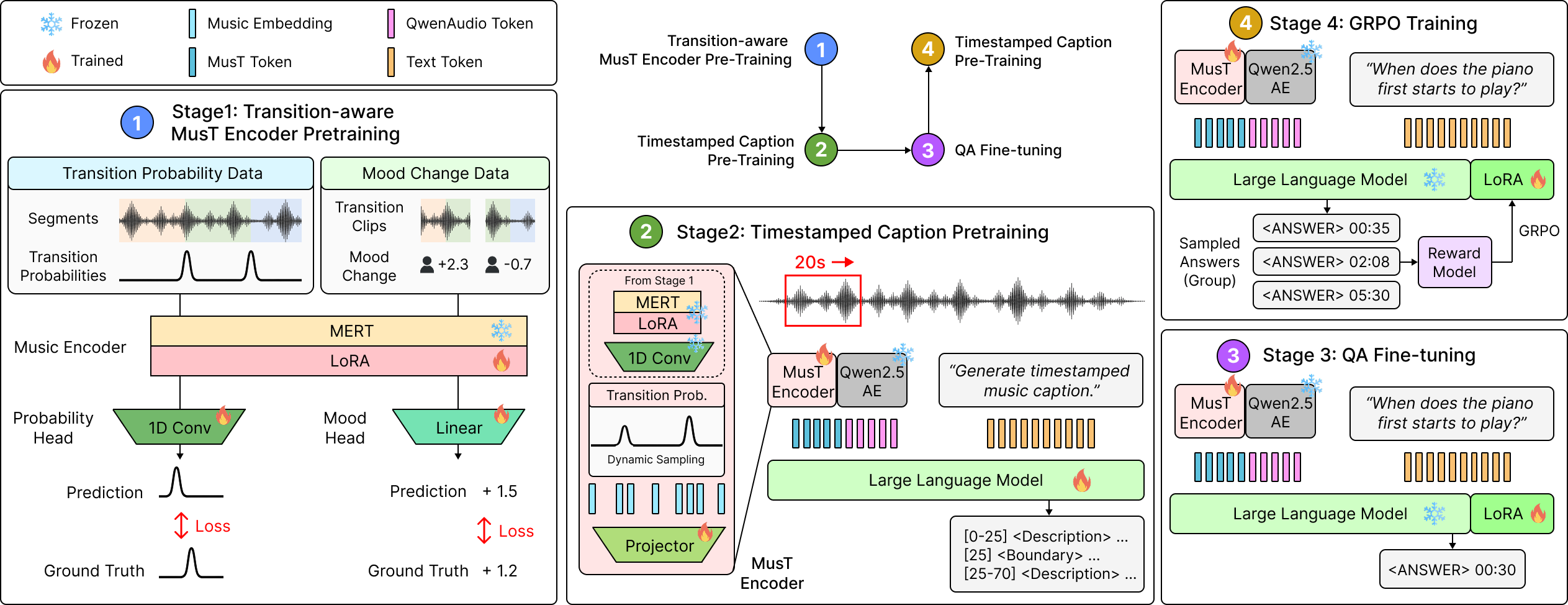
1. Transition-Aware Encoder Pretraining
Adapts the music encoder to capture transition probability and mood-change signals.
2. Timestamped Caption Pretraining
Aligns acoustic tokens with timestamped music captions.
3. Temporal QA Fine-Tuning
Trains the model on five temporally grounded QA tasks.
4. GRPO Training
Optimizes timestamp and interval predictions with task-level rewards.
Citation
@article{kwon2026mustbench,
title={MusTBench: Benchmarking and Advancing Temporal Grounding in Music LLMs},
author={Kwon, Daeyong and Wu, Qiyu and Kuriya, Shinobu and Koo, Junghyun and Cui, Shuyang and Zhong, Zhi and Liao, Wei-Hsiang and Wakaki, Hiromi and Mitsufuji, Yuki},
journal={arXiv preprint arXiv:2605.29300},
year={2026}
}